

Yu cong
Assistant Judge of Hongkou District People’s Court, Shanghai
principal items
introduction
First, the short-board view: the intelligent information challenge faced by the trial situation data analysis
Second, the origin: the restrictive factors of deep mining and application of trial situation data analysis
Third, the construction basis: the interpretation of DQM data quality management in the analysis of trial situation data.
Fourth, the way of transition: the practical path of the trial situation data analysis and operation department
tag

The informatization construction of people’s courts has entered the "knowledge-centered" 4.0 era, but the massive data collected by the courts in judicial activities have not played an equal role. Through the analysis of the running situation of the court trial, the shortcomings lie in the scattered data analysis, the emphasis on management and the neglect of user orientation, the hidden data security and hidden dangers, the insufficient conversion rate of feedback results, etc. The restrictive factors lie in the misunderstanding caused by ranking tendency, the increase of "scissors effect" in technical barriers, and the difficulty in building a professional operation system with heterogeneous data sources. Therefore, it is necessary to manage the public data resources obtained by the court as natural resources like minerals and set up a special data operation department. Secondly, from the perspective of DQM data quality management, it deduces the process from the aspects of data audit, data processing, data service and data application, and provides development path guidance for setting up specialized data operation departments from the aspects of operating principles, staffing, workflow and system function realization.

introduction
The analysis of trial operation situation is to extract the "wind vane" and "barometer" that can reflect the national economic and social development from the massive case information. After entering the era of big data, artificial intelligence, blockchain, and 5G, the core technology of informatization has been iteratively upgraded, and the connotation and extension of smart courts will inevitably expand to a new breadth and depth. The informatization construction of people’s courts has developed from version 2.0 with interconnection as the main feature to version 3.0 with data as the center, and now it is "basically completed by the end of 2022 and fully completed by the end of 2025 with information version 4.0 with knowledge as the center". Promoting the application of big data in the judicial field is the realistic demand of China’s judicial reform. The deep integration of science and technology and judicature has always resonated with the trend of the times. How to make them complement each other and cooperate organically has become an important topic facing the people’s courts at present.
First, the short-board view: the intelligent information challenge faced by the trial situation data analysis
As one of the basic functions of trial management, trial situation analysis plays an important reference role in grasping the development trend of trial field and making decisions by court leaders. Regular trial situation analysis will not only help statistical analysts to improve the quality of information collection, but also help the trial management to formulate relevant management policies and contents in a targeted manner and adjust management strategies in time. At the same time, it will also help the country to analyze from a holistic and overall perspective and provide reference for the country to formulate policies. According to the work layout and overall thinking during the 14th Five-Year Plan period, the informatization construction of people’s courts in the future should focus on building China characteristics, leading the innovation trend of Internet justice in the world, improving the ability and level of serving economic and social development, and realizing a higher level of digital justice.
Data analysis is multi-discrete, which increases the burden of secondary processing.
With the gradual advancement of the construction of smart courts, courts all over the country are constantly showing the coexistence of unity and diversity, and micro-innovations that meet the characteristics of local needs are emerging one after another, but it also leads to a serious shortage of coverage of judicial data in the original legal standard system, and the problem of mutual separation between business line systems is particularly obvious in data analysis. Due to different functions and powers, various departments have developed different data platforms and published their own data analysis reports on a regular basis, resulting in the coexistence of multi-departmental statistical data. Due to the different ports of data acquisition system, the degree of automation and timeliness of data acquisition are different, and there are also different data generation methods (Figure 1). The name fields of the same data are different in different systems, and the statistics of the results are also different. The accuracy and consistency of the data cannot be guaranteed, which brings great difficulties to the use of judicial data. In addition, although a large number of data and reports are generated automatically or manually, a large number of data are scattered, so it is difficult to collect them by customization and the visualization is insufficient. When writing data reports or analyzing a certain kind of cases, the collected data need to be processed twice, which can not be obtained by customized means of informatization, but it increases the workload, which goes against the convenience of informatization to some extent and even returns to the old road of manual data collection.
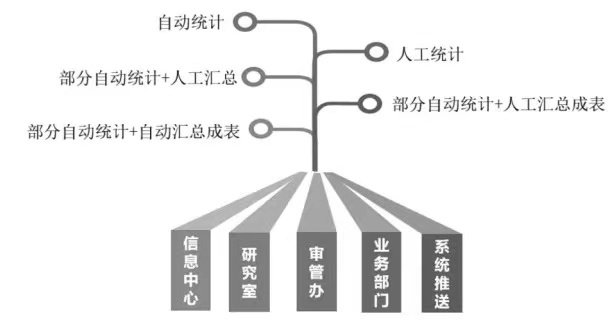
Figure 1 Existing statistical management departments and statistical methods
The function does not match the demand, and management is emphasized while user orientation is ignored.
On July 1st, 2014, the People’s Court Big Data Management and Service Platform was officially launched. Now, the platform can dynamically update the case information of 3,525 courts in China every five minutes. Based on 138 judicial statistical reports, it can automatically generate 5.8 million reports for the national courts on a monthly and annual basis, make a visual and multi-dimensional case trial situation analysis, and automatically generate trial situation reports including case ranking and cause analysis on a regular basis (as shown in Figure 2). However, in practice, the platform has not been used in all courts, and the report generation of local courts still depends on the comprehensive trial system in various regions. The uneven development of informatization leads to the mismatch between functions and needs. The analysis of trial situation is closely related to the quality and efficiency evaluation of each hospital, and it is linked to the performance appraisal between courts. Therefore, there is often a phenomenon that the leadership pays attention to the overall trial situation, tends to be indexed gradually, and carries out management work with results as the guide, which leads to the fact that the results are valued over the process, and the management is valued over the user’s guidance. Under the pressure of performance appraisal, the judges make the court’s data informationization work and trial management appear "two skins".
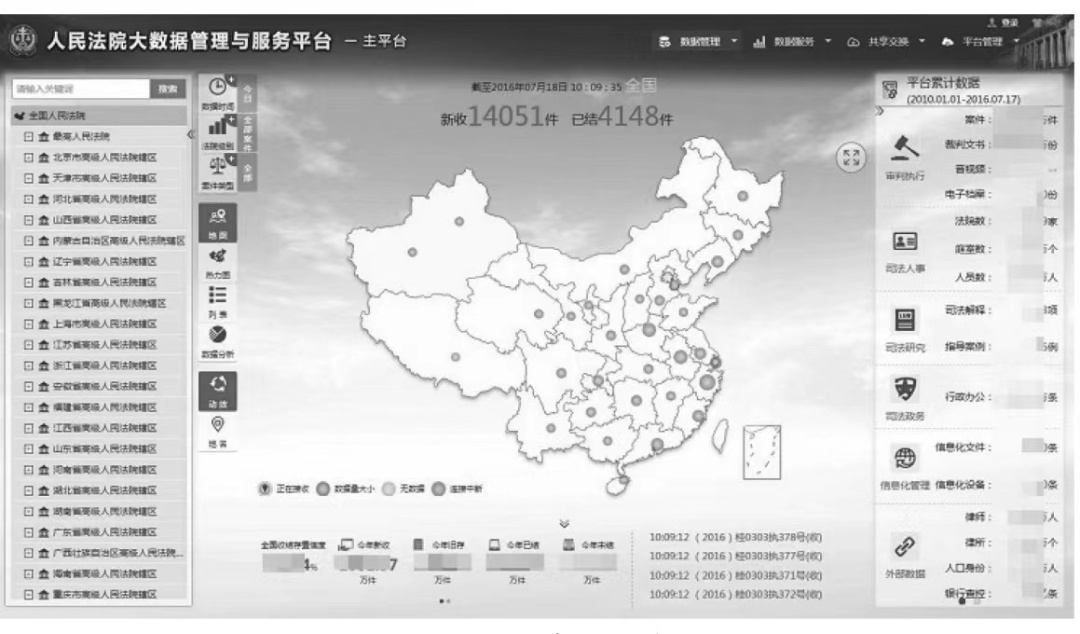
Figure 2 Interface of People’s Court Big Data Management and Service Platform
Lack of application cooperation norms, hidden data security and hidden dangers.
In 2020, the Supreme People’s Court organized an investigation and evaluation for the national courts, and evaluated the sunshine application effect of the national smart courts in 2020 from the aspects of court judicial openness, litigation service and judicial publicity (see Table 1).
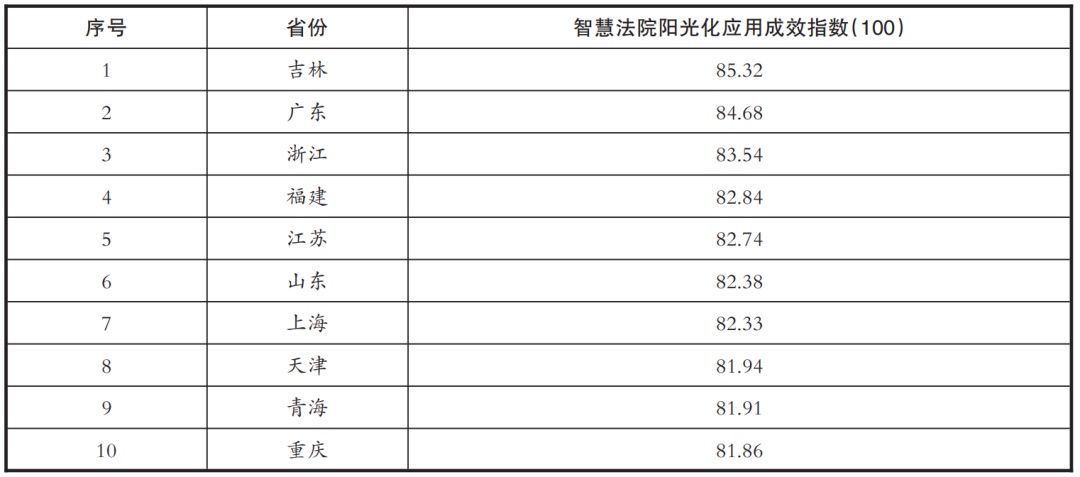
Table 1 National Wisdom Court Sunshine Application Effectiveness Index TOP10
Source: Evaluation of National Smart Court Construction in the Supreme People’s Court in 2020.
At present, 91.7% of the courts in China have realized the connection between the science and technology courts and the trial system, and a total of 2,169 courts have five functions: synchronous generation with cases, intelligent cataloging of cases, digitized electronic files, online marking and automatic filing of electronic files. In terms of cooperation in court informatization construction, Zhejiang Higher People’s Court and Alibaba Group signed a strategic agreement on the construction of judicial big data platform, Guizhou Higher People’s Court served judicial work by building a political and legal big data sharing platform, and Shandong Court built "Shandong Court Data Service Cloud Center" to centrally store, develop and apply all kinds of data. Security is the foundation of court informatization, and it should be the logical starting point of all construction. According to statistics, the construction of data security and cloud security in people’s courts is still in its infancy, which obviously lags behind the application. Less than 60% of the high courts have initially carried out cloud security construction, and have basic protection capabilities such as cloud hosts and cloud applications; Only the Supreme People’s Court and about 35% of the high courts have initially carried out data security infrastructure in data classification, data encryption and data audit. The visual quality and efficiency operation and maintenance management platform built in the Supreme People’s Court has the emergency takeover capability for only 25% of the application systems. In addition, due to the different development levels of information technology, unified methodological guidance and norms have not yet been formed. Some regions have signed cooperation agreements with enterprises to outsource departmental data and technologies. However, the high mobility of enterprise personnel has also increased the potential information security risks in disguise, and many problems have made the rapid informationization of people’s courts face greater risks.
Lack of data mining depth and insufficient conversion rate of feedback results
The data can not only be used to complete the "historical portrait", but also, because of the regularity implied in the data, the in-depth analysis of the data is helpful to predict the future trend. At present, the application results produced by the integration of big data and judicial trial, such as the case retrieval applications such as "smart trial" and "smart judge" that have emerged in courts around the country, and the China judicial big data service network, are limited to the field of judicial decision-making or trial quality and efficiency evaluation, and the data involved are mainly structured data, and the data value has not been fully tapped. According to the special statistics of big data published by China Judicial Big Data Service Network (see Table 2), a total of 45 special reports of judicial big data were published, which accounted for a very small proportion of the total number of trial and execution cases each year, and the effect in deep excavation was not satisfactory.
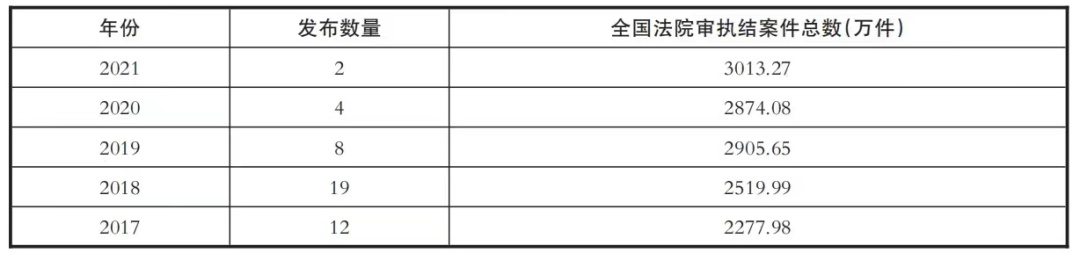
Table 2 Statistics on the number of special reports on judicial big data published in the Supreme People’s Court
The judicial data involved in the application systems used by local courts can only reflect the historical situation of a certain time section in a static, lagging and single way, and cannot be integrated to find problems in a predictable and dynamic way. In the era of big data, this does not meet the requirements of data analysis and utilization, nor can it meet the needs of court litigation services, trial execution, trial management, personnel management and other related work, resulting in low utilization rate of relevant data value development. In terms of transforming data into products, serving the public and the overall economic and social situation, the application effect is lower than expected, and it is impossible to really promote the construction of a "knowledge-centered" smart court, and it is temporarily unable to use judicial knowledge to solve complex problems in judicial activities and even social activities.
Second, the origin: the restrictive factors of deep mining and application of trial situation data analysis
While data resources release enormous energy, we are also facing data constraints and even crises. The root cause is that our cognitive level, technical support and governance system capabilities have not kept pace with the era of big data.
Idea: ranking tendency leads to understanding deviation
Good big data thinking and ideas will be conducive to the integrated application of big data in judicial trial activities, and also the key to the application of judicial big data and the realization of its core value. In the era of big data, the breadth and depth of court informatization depends on the theoretical basis of justice itself, and technology is only a icing on the cake, making it from ideal to reality. However, some judges have formed traditional thinking patterns and inertia in their long-term work. In the era of rapid development of information technology, they will inevitably feel at a loss. Their understanding of judicial big data simply stays at the level of data statistics, and they think that the analysis of case collection trend, case closing balance and trial quality can cover the boundaries of judicial big data, paying less attention to the deep application value of judicial big data, and lacking understanding of the value and interaction effect of data resources. In addition, the analysis of trial situation is to quantify the data, and some of its disadvantages will also lead to excessive pursuit of ranking, detract from the substantive role of management, and increase the burden for the tendency of administrative management. The above problems will lead to a great waste of judicial resources, thus hindering the healthy development of the application of judicial big data. If the thinking concept is not changed in time and the trial situation data analysis is regarded as neutral technical management, the application of judicial big data will be inefficient and chaotic.
Technology: Barriers increase the "scissors effect"
1. The accumulation of "dark data" hinders the utilization.
The integration of artificial intelligence technology and court work is in the development stage, and the algorithm still needs innovation and breakthrough. There is a significant "scissors difference" between data processing capacity and data resource scale, and it continues to expand. By combing the existing court data information points, we can see that there are both structured data such as normative legal terms and legal documents with relatively fixed formats, and unstructured or semi-structured judicial data. The latter is more technically difficult than the former, and it is even more difficult to intelligently transform and apply it through big data, which leads to a large number of data being "dark data" with unknown value because it is impossible or too late to process. In addition, big data algorithms in various industries have a "black box" effect to some extent, which means that big data processing and decision-making behavior are invisible. Because the specific algorithm is usually mastered by technicians, it is difficult for court staff and the public to know the operation process and specific values of the algorithm, which will also bring about the contradiction between the secrecy of big data algorithms and the openness of judicial decisions.
2. Limited application makes it difficult to achieve a breakthrough.
The rapid development of smart courts has made great achievements, but there are still some important technologies related to judicial core business that are currently in the pilot or exploration application stage, such as mobile case handling, mobile marking application, paperless case handling in the whole process and other system applications still need to be vigorously promoted and the scope needs to be expanded. Only by accelerating the pace of such technical means that can greatly improve the quality and efficiency of trial execution can we meet the rapidly growing social and judicial needs. In addition, some physical facilities and system functions have not fully played their due roles in practice. For example, China Mobile Micro Court currently covers the main functions of online filing, case inquiry, litigation payment, pre-litigation mediation, mobile phone marking, computing tools, court navigation, cross-domain filing, etc., and some equipment in litigation service halls consumes a lot of construction funds, but there are problems of duplication or omission of functions.
System: A professional operation system with multi-source and heterogeneous data is difficult to build.
Massive data will interact with the surrounding environment in matter, energy and information, forming an open complex giant system. Data collection also brings risks. Because of the antagonistic development of data mining, analysis and processing technology and data desensitization technology, the data volume is huge and grows rapidly in multi-dimensional application scenarios, which poses a more severe challenge to data control ability. During the trial execution, the court collected a large number of public data resources. However, the court itself does not have the professional ability of data resource operation and management, and most of them entrust specialized technology companies to carry out related work. However, it is difficult to divide the responsibilities clearly in this mode. According to the White Paper on Government Data Quality Management released by the evaluation section of China Software Evaluation Center in December 2019, by the end of November 2019, 22 of the 32 provinces (autonomous regions and municipalities directly under the Central Government) in China (accounting for 68.8%) had defined the overall government data management institutions (see Table 3). Data management is carried out by means of government departments and internal organs of government departments, so as to rationally divide responsibilities and strengthen overall planning.
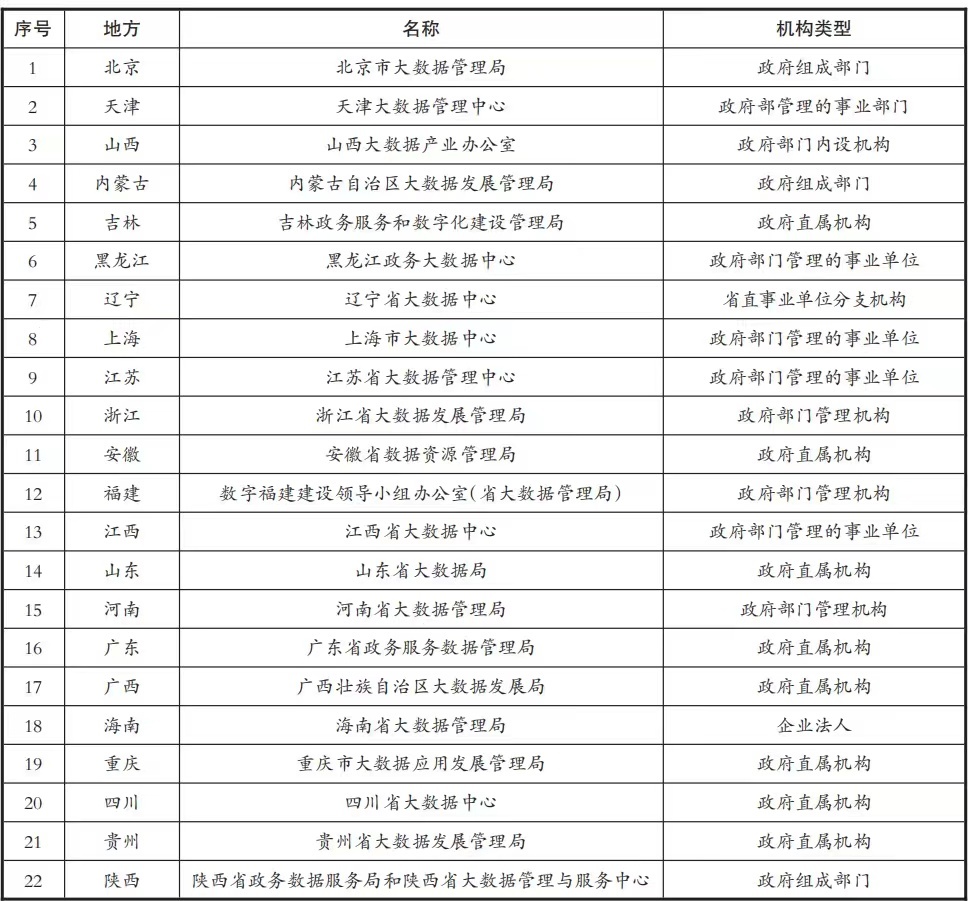
Table 3 Establishment of data management institutions in all parts of the country
To sum up, in the era of big data, data resources, as an important national strategic resource, have the responsibility of safeguarding national security externally, and the responsibility of safeguarding the public rights and interests of individuals and enterprises internally. It is necessary to manage the public data resources obtained by the court as natural resources like minerals and set up a special data operation department.
Third, the construction basis: the interpretation of DQM data quality management in the analysis of trial situation data.
In order to promote the breadth and depth of trial situation analysis, the court system should introduce Data Quality Management (DQM) to provide guidance for setting up a special data operation department. Data quality management refers to a series of management activities, such as identifying, measuring, monitoring, early warning and so on, which may cause various data quality problems in every stage of the life cycle of data from planning, acquisition, storage, sharing, maintenance, application and extinction, and further improves the data quality by improving and improving the management level of the organization. Data quality management is a circular management process, and its ultimate goal is to enhance the value of data in use through reliable data. And ultimately win economic benefits for the enterprise. The optimization idea of its application process is as follows (as shown in Figure 3). Data quality management is not an additional process, but a specific data processing process to be incorporated into the court, which can be interpreted as data audit, data processing, data service and data application.
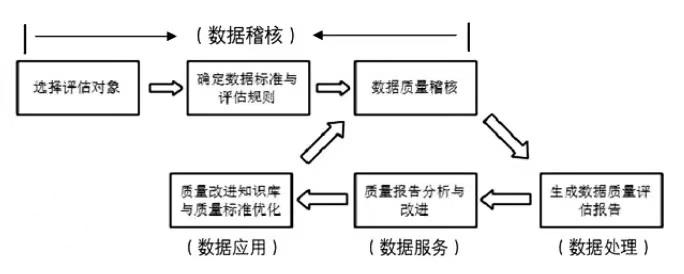
Figure 3 Data Quality Management Process for Court System
Data auditing pursues objectivity and accuracy.
Big data is not only a huge data set, but also a complete set of data in a certain field formed by the aggregation and correlation of multiple data, and the "data pool" can produce value. Data audit is a process to realize data integrity and consistency check and improve data quality. As the basis of database management and control chain, its main attribute indicators include accuracy, integrity, consistency, uniqueness and timeliness. Data quality management is the premise of data analysis. The trial situation data analysis and operation department should combine the above indicators to summarize the data formed in the whole process of court trial management activities, such as filing, mediation, preservation, evidence submission, trial, after-court collegiate bench, document writing and filing, and use standardized processes and tools for screening to ensure the objectivity and accuracy of data pool data.
Data processing pursues scientific specialty
"When we are waiting for more powerful computers, smarter software and updated human technology, it is obviously not enough to accumulate data." In the era of big data, with the rapid growth of data volume, the rapid acceleration of data changes and various data sources, more data enters the data processing system in the form of continuous input. Efficient processing of continuous data and extracting true, accurate and valuable characteristic results from it are not only important indicators of the data quality management system, but also extremely important for the processing efficiency of the big data processing system and the embodiment of the application value of big data. This stage is an important step to continuously improve the data quality (as shown in Figure 4). Through continuous cycle analysis, the quality of data display can be improved, so as to obtain more scientific analysis results and add help to the trial situation analysis.
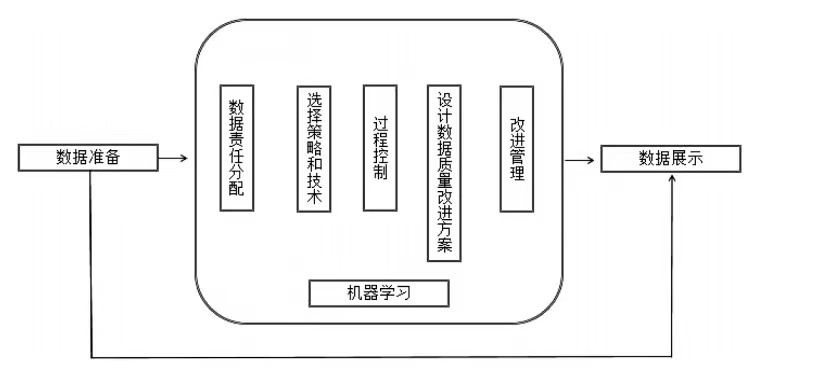
Fig. 4 control flow chart of data processing process
Data service pursues high efficiency and convenience.
Trial management should be service-oriented in nature, similar to court management. The mainstream academic circles also hold the basic attitude of "limiting" and "guarding" on trial management. That is to say, compared with the subject judicial behavior, the trial management with judicial behavior as the object should be service-oriented in nature, which requires that there should be a clear and clear boundary between trial management and individual trial of judges, and trial management should serve the judicial trial, but not influence the judge’s trial. Therefore, the realization of "judge’s initiative" and "court’s restraint" is the institutional choice for the reform of court trial management system. The establishment of the trial situation data analysis and operation department not only ensures the objective and efficient data collection and convenient data maintenance, but also serves the staff, frees the clerk or the assistant judge from the administrative routine work, and replaces the repetitive input and other labor work with science and technology. The data service includes not only the service of trial execution and judicial management, but also the service of the people, so as to realize the efficient and convenient service by specialization, so as to better fulfill the purpose of ensuring the good operation of court trials.
Data application pursues value release
The hidden value behind massive data is not only related to each case, but also contributes to the development of society. Based on the traditional data analysis mode of statistical technology, judicial data can only reflect the historical situation of a certain time section statically, lagging behind and singly, and cannot be integrated to find problems predictably and dynamically. In the era of big data, this does not meet the requirements of data analysis and utilization, nor can it meet the needs of court litigation services, trial execution, trial management, personnel management and other related work, resulting in low utilization rate of relevant data value development. At the same time, the data in the judicial field is wide-ranging and professional, and the data characteristics are often hidden deeply, which makes it difficult to build a judicial knowledge system. Mining potential, hidden, possible, special relevance or relational data or information from the data pool, which may point to previously unknown patterns, internal relations, laws, development trends, etc. It is a key step from data mining to knowledge discovery for court leaders to make decisions by using these emerging data and information. On the basis of objective and accurate data, professional data analysis and efficient data service, the trial situation data analysis and operation department cultivates and improves data mining ability, which is the best practice of organically integrating judicial laws and scientific and technological achievements.
Fourth, the way of transition: the practical path of the trial situation data analysis and operation department
In the future, it is necessary to continuously increase the depth and breadth of the use of trial management information, so that the developed judicial management system can be used more deeply. The connotation, framework, mode and mechanism of court data governance need to be further explored. It is the general trend to integrate data governance with business processes and comprehensively use rules and technologies to achieve collaborative governance, and data governance has gradually become a new hot spot and concern.
Operating principle
1. Principles of data security
On June 10, 2021, the Data Security Law was reviewed and approved, and will come into force on September 1, 2021. As a new and independent protection object, "data" has been recognized by legislation. Data security runs through the whole process of data development and utilization activities. With the practical application and business, data remains and flows between different carriers, and runs through all levels and links of court information activities and trial business. The trial situation data analysis and operation department should follow the relevant provisions of the data security law, master information security knowledge, enhance information security awareness, strengthen information security management in information research and development applications, actively and comprehensively defend against all kinds of information security risks, and eliminate all kinds of security risks.
2. The principle of big data instrumentalism
The process of judicial activities is not a mechanical determination of facts and the application of laws, but also includes the judge’s balance of social values behind the case, the perception of human nature, the judgment of moral norms and the realization of judicial functions. Important aspects other than these cases are difficult to be covered by big data algorithms. Therefore, to set up the operation department of trial situation data analysis, we should adhere to the positioning concept of big data instrumentalism, and not fall into the one-sided and technical omnipotence of data supremacy and technology supremacy, otherwise there will be a situation of alternative justice that usurps the host’s role and occupies the nest. In June 2019, France formulated and implemented the so-called "prohibition clause" of judicial big data to prevent the application of judicial big data, infringe on the privacy of judges, hinder judicial justice and damage judicial authority. Once you fall into blind admiration for big data technology, unilaterally exaggerate the utility and function of big data, ignore the risk of defects in the technology itself, and even cover up some non-technical and very important issues intentionally or unintentionally, which will only cause "internal injuries" in judicial trials.
Staffing
In the process of establishing the trial situation data analysis department, the setting of position system will directly affect the efficiency and quality of data analysis. Because data activities need both rigor and innovation, it will involve new personnel, such as scheme architects, data acquisition engineers, big data researchers, etc., and will also strengthen the new vitality of the original positions, such as judicial administrative equipment department, information management department and other departments. This paper believes that the data operation department can be composed of the following categories of personnel:
Basic platform category: it is divided into two categories: hardware platform and software platform. The hardware platform includes server, operating system and network maintenance, which can be mainly undertaken by the existing judicial administrative equipment department, information management department and other departments. Similar to the current work, it is to add more operational content about big data system on the basis of the original work; The software platform includes data warehouse management, software system operation and maintenance, etc., and new technicians need to be introduced.
Technology research and development: Technology research and development jobs refer to the development of systems, software, products and functions related to big data. Because the development of big data is a relatively complete work chain and has special application requirements and scene characteristics, this kind of personnel also need to involve new technicians.
Product design category: Project design category is the basic premise of planned data development, which usually determines the future direction of a product or project and the concept definition of specific implementation. This kind of personnel can be new technical personnel, but also need to be transferred from the trial management department to design the future data operation direction from the perspective of court trial management.
workflow
Daily data analysis: the trial situation data analysis operation department undertakes daily data analysis, and all data enter the data operation management system after quality audit and inspection, and are sorted out by the data operation department and then added to the data pool. According to different work contents such as trial situation analysis, trial management, qualitative and effective data analysis and judicial statistical analysis, the daily data analysis work is completed, and the technical means are used to continuously improve and optimize, and finally the data analysis results are submitted.
User-defined requirements: each business department puts forward user-defined requirements, such as special data requirements for manuscript writing, reference for analysis and judgment of types of cases, case retrieval reports, etc. After sending them to the data operation department, the data will be analyzed, improved and optimized, and finally an analysis conclusion will be drawn for work reference.
Whether it is daily data analysis or user-defined requirements (as shown in Figure 5), all data flows in this process will also become memory data and become an important part of data pool expansion. In this process, the daily data analysis is more important to realize the centralized and flat management of data, which greatly saves the statistical analysis workload of the original staff and avoids repetitive work. User-defined requirements promote the application and deep mining of data by putting forward requirements, so as to continuously improve and improve data management.
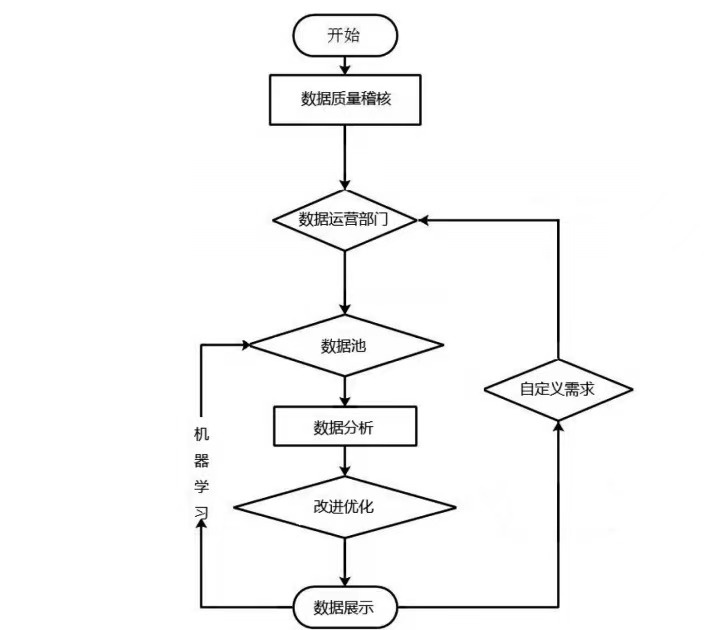
Figure 5 Work flow chart of trial situation data analysis and operation department
System function realization
Progressive system function realization of trial situation data operation analysis department (as shown in Figure 6):
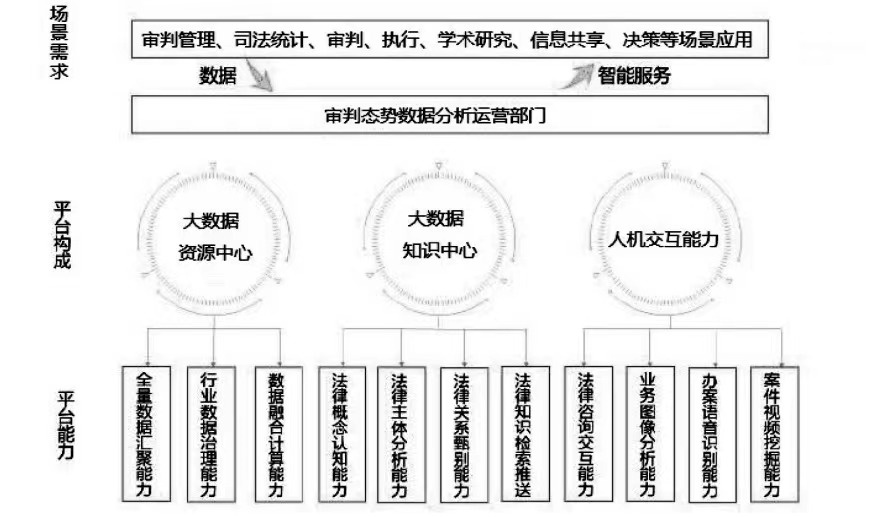
Fig. 6 Scenario implementation of trial situation data operation analysis department
1. Gather data
Faced with such a large amount of data in the era of big data, it is urgent to establish a professional department to process these data, and then make statistics, analysis and prediction of the data. Today’s data has reached a great order of magnitude, and the limitation of data volume is disappearing. Collecting data in an infinitely close way of "sample = population" will hide surprises for the future refined operation of data.
2. Fusion data
The life of judicial data lies in its application, but judicial data often includes a lot of implicit knowledge that is not explicit. Therefore, in order to effectively apply judicial data, scientific fusion analysis and data mining must be carried out first. By exploring the establishment of data fusion rules, analyzing and refining semi-structured and unstructured data according to legal knowledge, realizing the same data fusion of structured, semi-structured and unstructured data based on semantics, and establishing data association relations, a highly integrated data resource map is formed to solve the problems of data integrity, consistency and correlation.
3. Data sharing
First of all, it is committed to achieving full coverage of information and smooth information flow, and building an integrated system integrating internal case handling system with judicial disclosure, litigation service, communication and publicity. For the outside, it is necessary to closely combine the trial management of people’s courts with the services provided for litigation participants and relevant public authorities to realize an integrated and integrated judicial information system. The internal case information management, case quality evaluation, case quality evaluation, trial process management, trial situation analysis and trial performance evaluation are organically combined with external sunshine justice, judicial openness, litigation service, information release, communication and publicity, and integrated into the overall construction of smart courts to jointly promote the realization of judicial justice and the improvement of judicial efficiency.
4. Data governance
On the basis of strengthening the top-level design of people’s courts’ informatization and giving full play to the functions of big data management and service platform, we use judicial knowledge engineering to solve complex problems in judicial activities, and then support model learning, reasoning and decision-making through large-scale background knowledge from data sources such as laws and regulations, judicial trial information resource database and informatization standards in the judicial field, so as to provide intellectual reference for social activities, promote the construction of "knowledge-centered" smart courts, and contribute China’s judicial wisdom to the modern transformation and transition brought about by data governance.
tag
It is not a simple matter to fully release the data value of the information "rich mine" of the court, which largely depends on building a scientific and reasonable data governance system. The establishment of a special operation department for trial situation data analysis is a preliminary attempt with the help of the wings of big data. Although many mechanisms and supporting measures, the existing institutional foundation and background are not in an ideal state, it is a useful attempt. Through a professional, standardized and systematic process, the whole process of data management and development from planning, acquisition and storage to maintenance, sharing and application can be realized, trying to solve the problems of unclear rights and responsibilities, numerous barriers and bottom line security that hinder the deep mining and application of data, and truly realize the transformation of smart court construction from internet and data-centric to knowledge-centric, so that the knowledge contained in big data can become the core driving force to promote the modernization of trial system and trial capacity.
